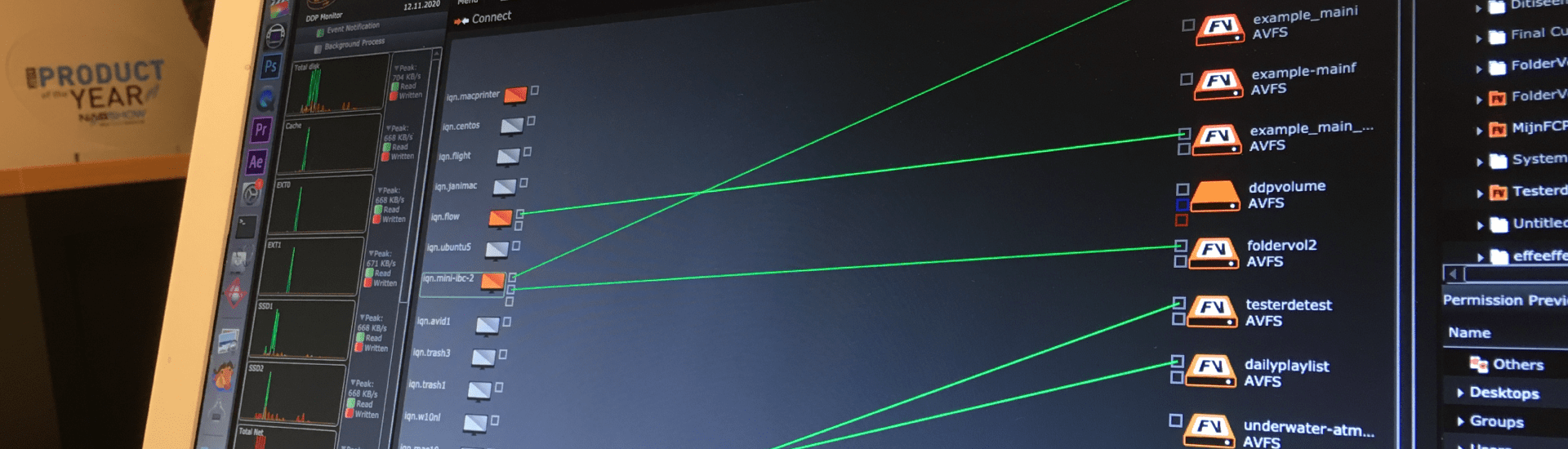
It is best to explain DDP technology via its web interface
DDP uses a single file system.
The name on the top right on the home page shows ddpvolume.
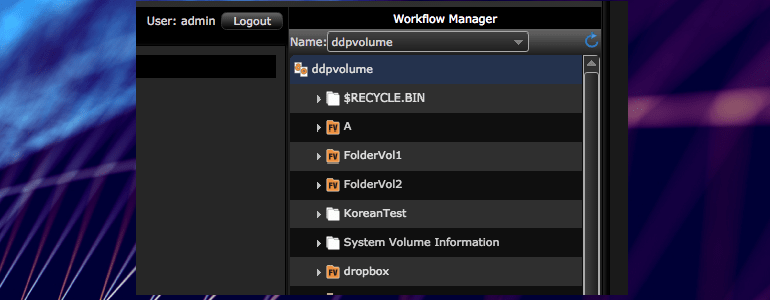
Ddpvolume is the name of the single file system. It is developed in house especially for M & E.
The single file system has one directory / folder tree, which is also shown on the right. The file system handles all metadata and is separate from the media.
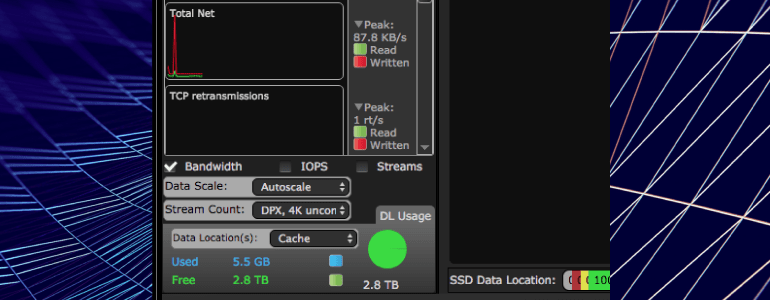
How and where is the media stored?
Media is stored as raw data in data containers called Data Locations (DL).
One or more raid or drive sets can be a Data Location.
Data Locations can be found at the bottom left. The file system controls on which Data Location a file is stored.
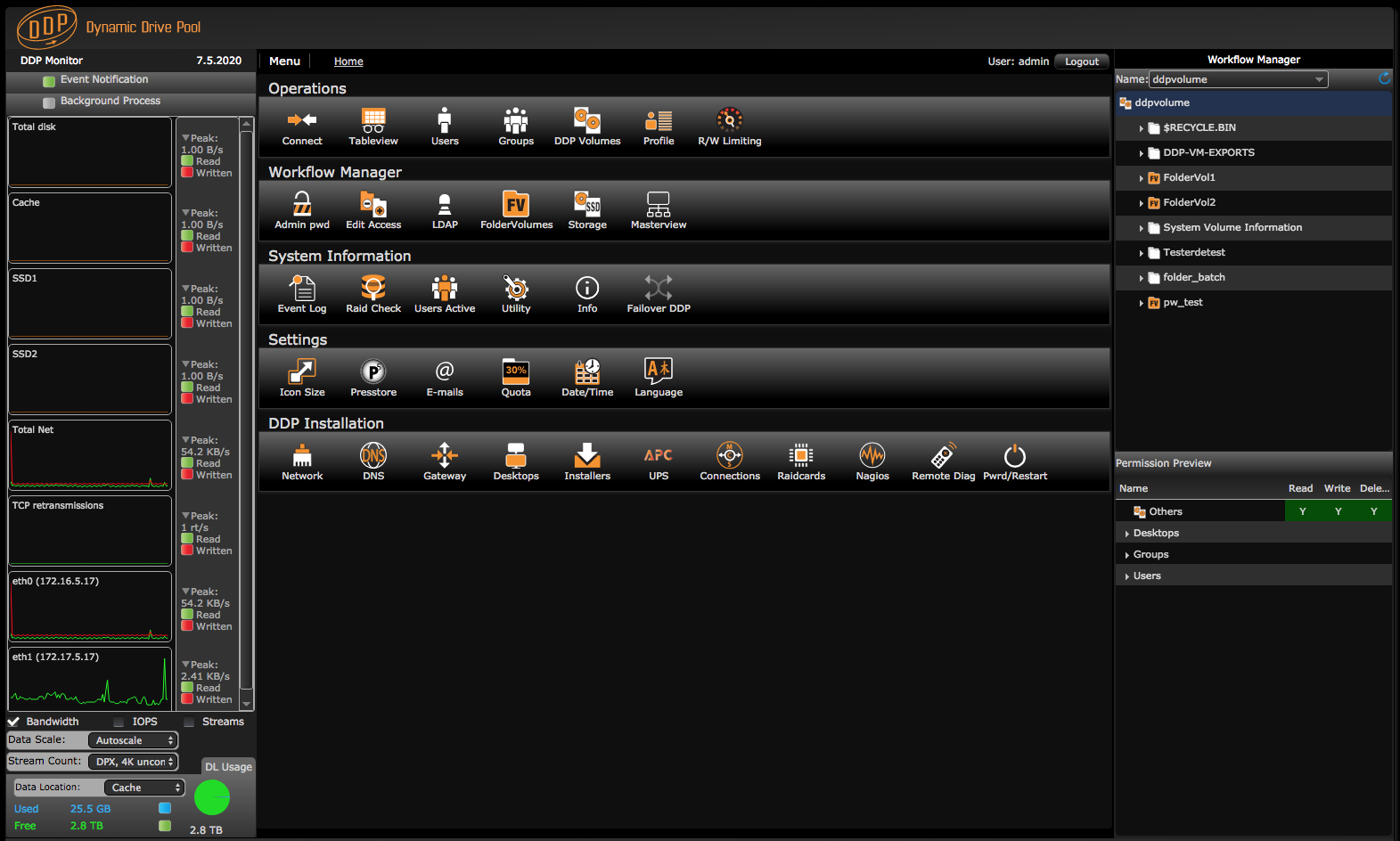
The homepage of the DDP webinterface
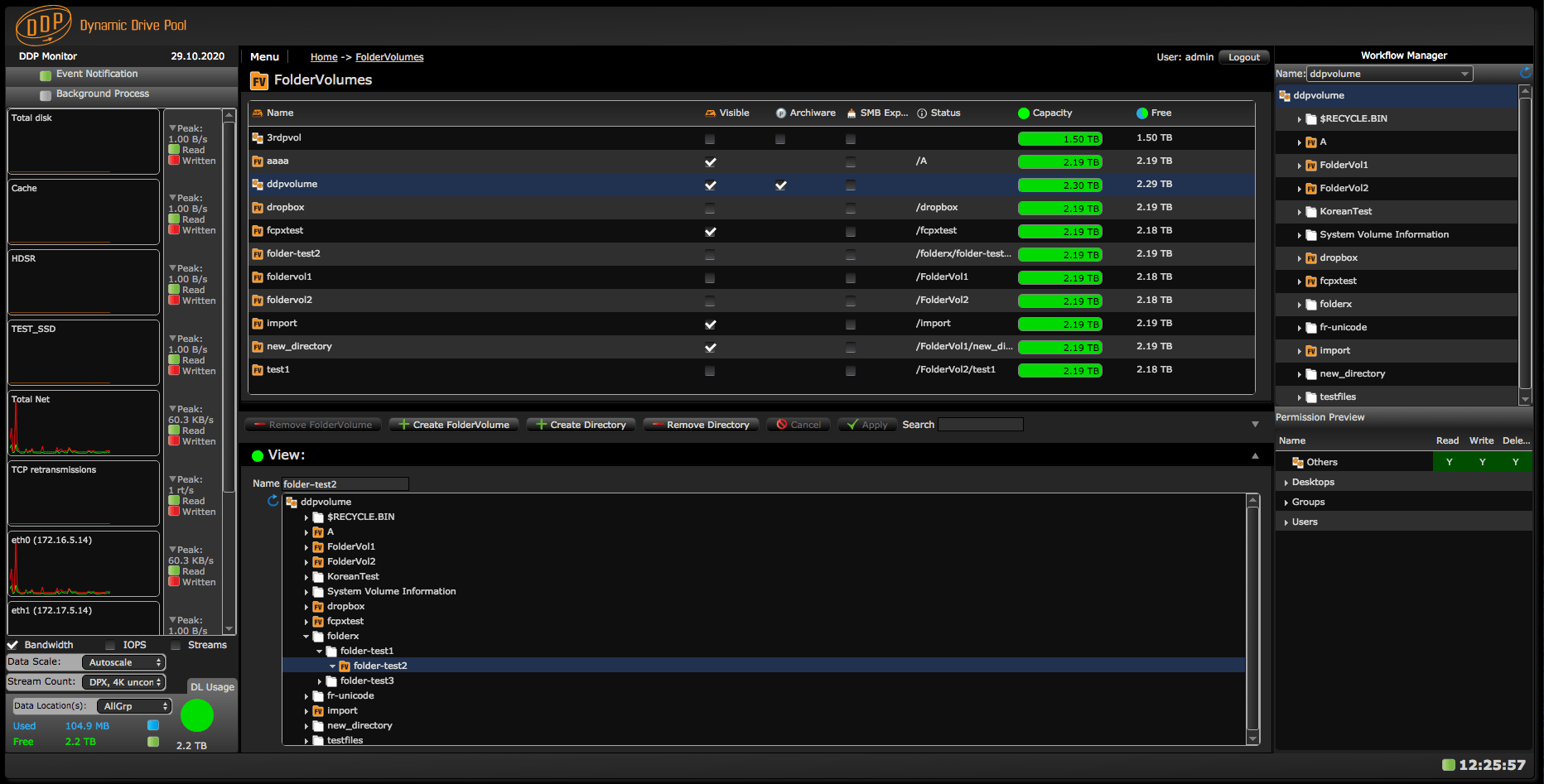
The Folder Volume page
How can a folder be connected to a desktop?
The first step is to add volume properties to a folder. That allowed these folders to be mounted as volumes. These are named folder volumes. Folder volumes can be created in the folder volume page. Each directory/folder can be made into a folder volume.
How to determine where a file is stored?
This can be done in the Storage Manager page by selecting Data Locations.
The selection can be per folder volume(s) or for ddpvolume.
The selection is inherited but can be changed anytime.

What happens when balanced is selected?
When there are two or more spindle (HD) Data Locations balanced can be selected. With balanced the first file is stored on the first Data Location and the second file is stored on the second. The performance for such directory/folder is the sum of the bandwidth of each Data Location separately. The seek time of spindles strongly influences performance especially when small files are present. With balanced seek time influence becomes less important, resulting in much better performance.

Can the Folder Volume/Data Location selection be changed any moment?
Yes and without the user noticing it. The next file lands then on the newly selected DL. Adding and selecting a DL in the form of HD or SSD packs or storage array can be done any time. The file system and directory/folder tree are not influenced by that. The DL added appears at the bottom left. The file system can also integrate storage of different configurations, build dates and brands.
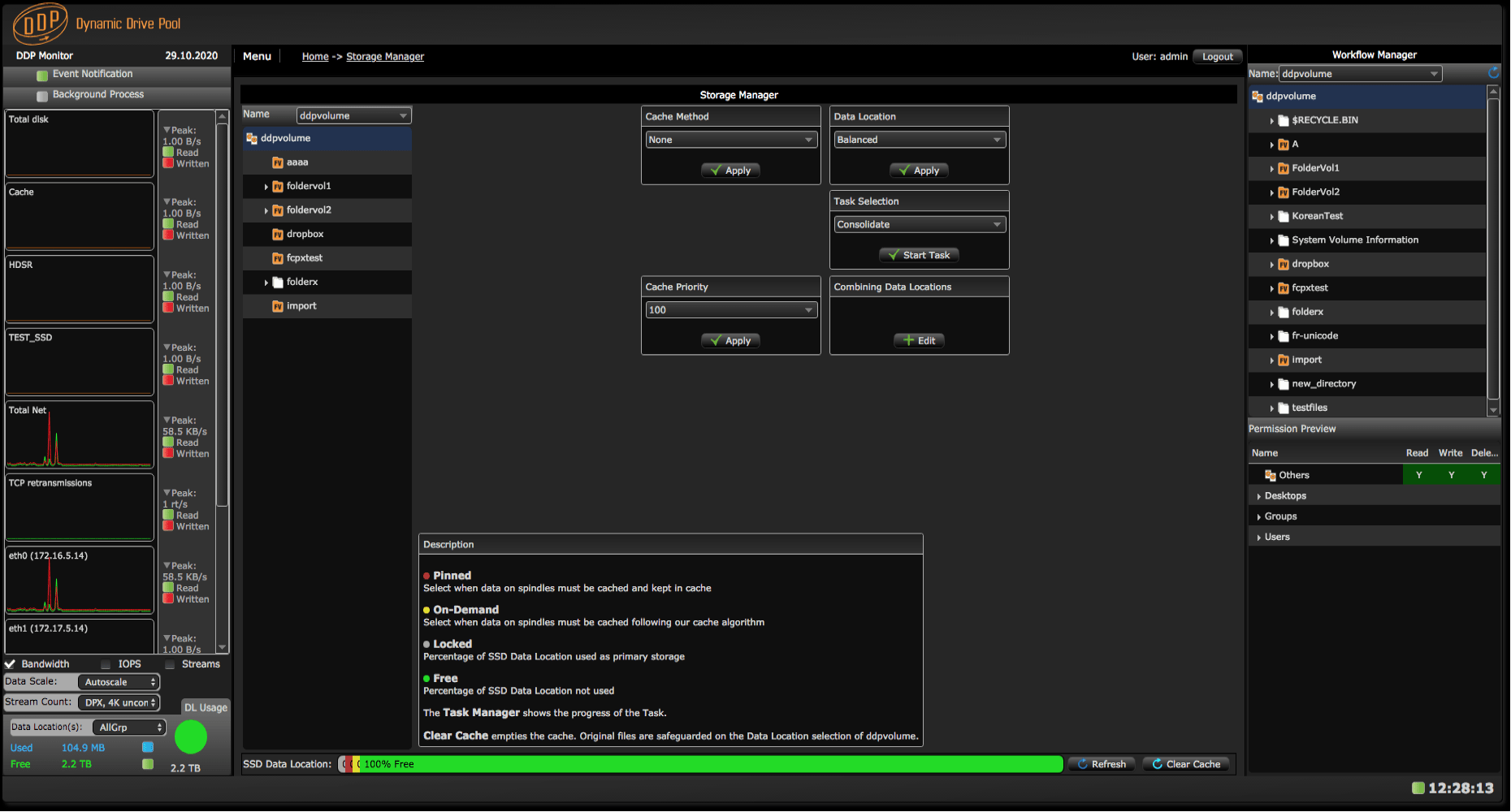
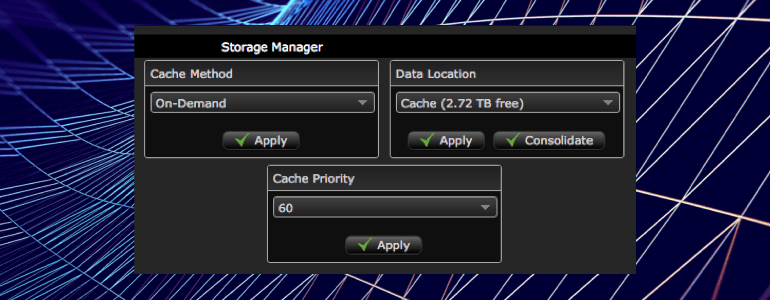
Balanced Storage Manager
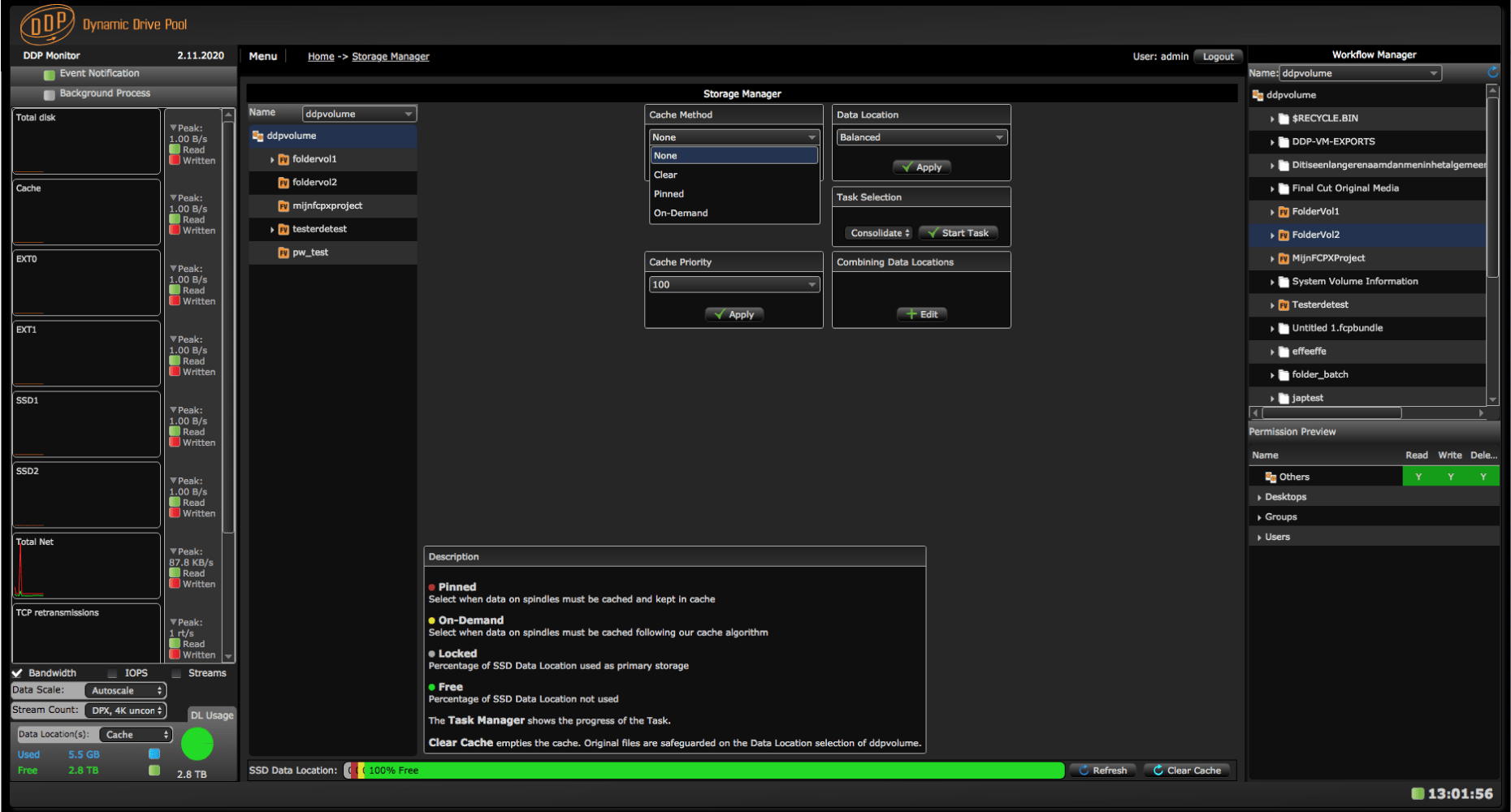
Cache Storage Manager

Why combine SSD and HD packs in a DDP?
SSD’s have no seek time. This makes the system bandwidth not depending on files sizes and fragmentation. Having a hybrid system (SSD and HD) combines the best of both worlds: SSD performance with HD capacity.

How are SSD and HD packs integrated in the DDP?
When an SSD pack is installed its Data Location can be used as file based cache. Files ingested in the cache are automatically duplicated on spindles. So files gone from the cache are taken from the spindles. Internally, transparent for users files can be moved, copied, duplicated, (re)distributed and consolidated between DL’s in different ways.
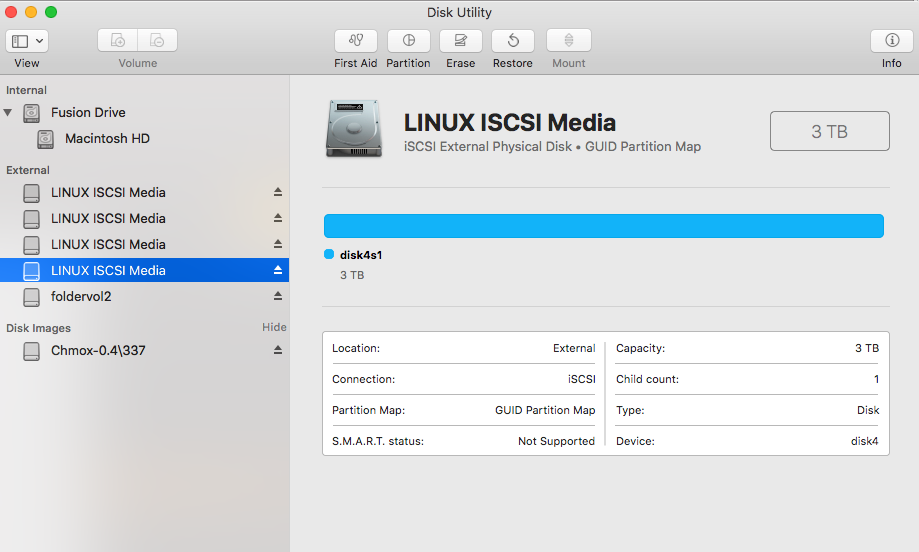
Data Locations
How do desktops access the DDP?
Desktops access Data Locations in parallel. Data Locations are mounted using iSCSI. An example is shown in Disk Utility of a Mac. In Windows this can found in Disk Management. The more Data Locations the higher the bandwidth. AVFS is a scale out file system because capacity and bandwidth can be increased separately.
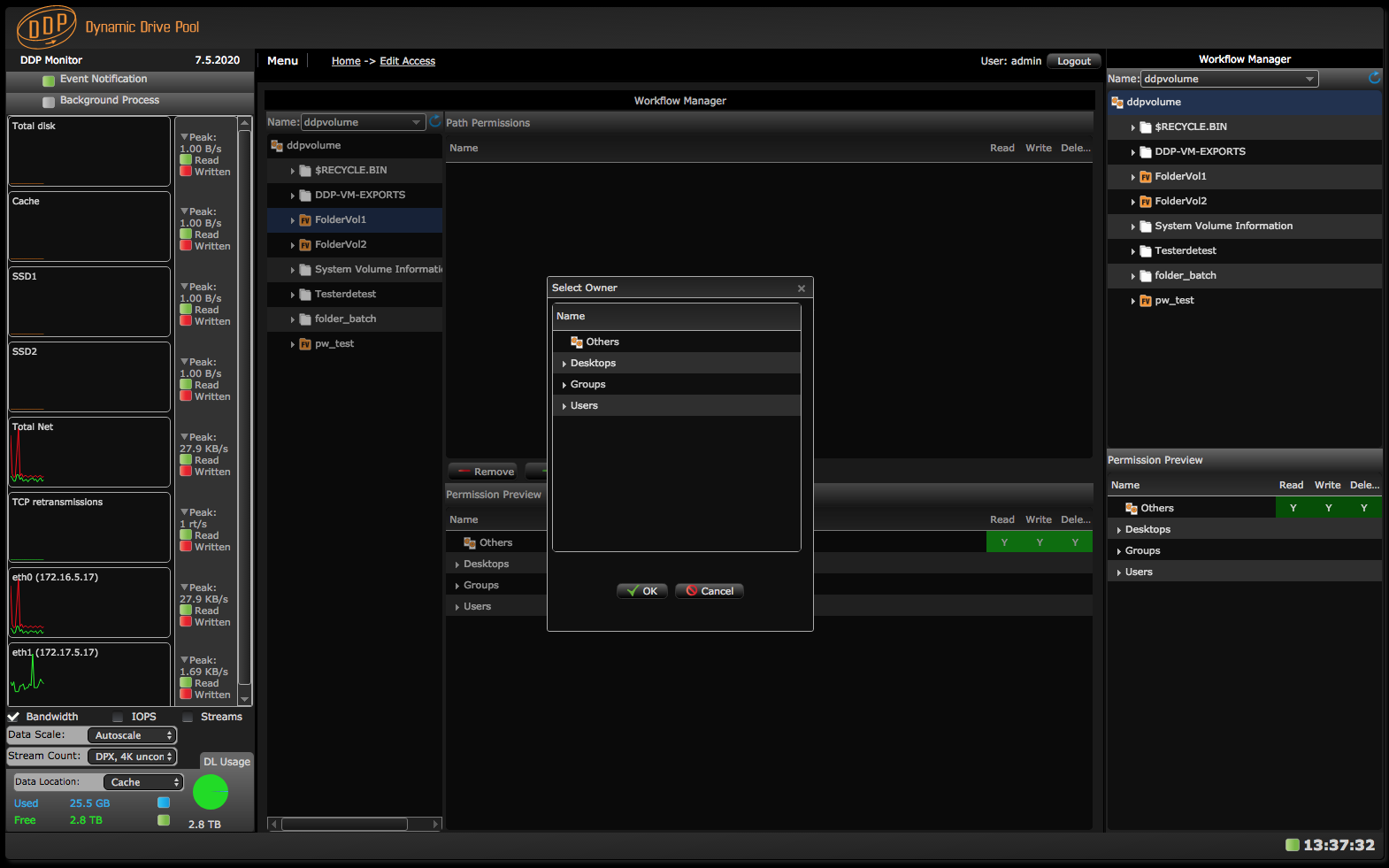
Edit Access page
How about access rights?
In M & E access right per user or group and per file is not necessary. Therefore user/group credentials are selectable per directories/folders. These credentials can be set in the Edit Access page on the DDP. User names can be entered manually or can be obtained and synchronized via Active or Open Directory or LDAP. The credentials of the AD, OD, LDAP users/groups are checked against AD, OD and LDAP.
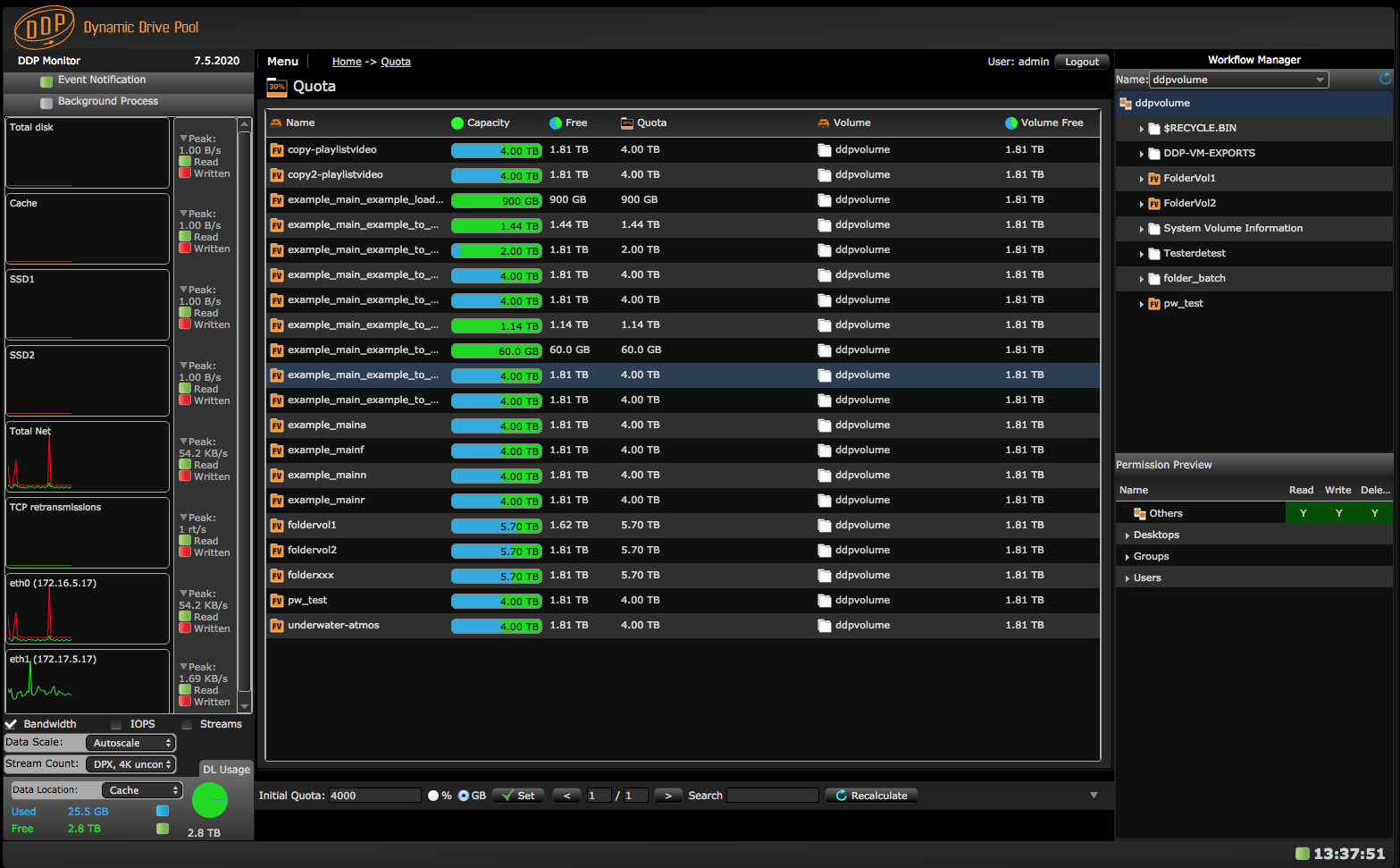
Quota page
How about Quota?
Quota can be set as folder volume property and can be changed dynamically. When files are deleted the capacity released becomes available in general. So no manual shrinking or expansion activity is needed. Every application but especially Avid benefits from this quota mechanism. This is because each folder volume can hold an Avid Media files directory and as such behaving as a workspace.
What about mirroring, backup, archiving & health monitoring?
The fourth row on the GUI Home page shows the Archiware P5 icon. Archiware P5 is installed on the DDP and comes with a standard AWB100 backup license free of charge. This license can be traded in for other licenses. These can be purchased from your dealer.
DDPs locally or globally can be kept identical (mirroring) using Archiware synchronise. Archiware archive is to archive and restore files to and from spindles, tapes and cloud. Archiware supports the major cloud protocols. Please check www.archiware.com for more information.
The home page contains pages to monitor the health of the raidcard(s) and disks. The IO of the system is monitored in the IO monitor on the left on the Home page. Also the long term history of the IO can be monitored when selecting Nagios. Nagios is also installed on the DDP and is available optionally to monitor chassis components and possibly other devices using SNMP.

How does caching function?
The DDP uses a file level cache, a ram level cache and optionally a block level cache. For a file and block level cache at least one SSD pack is required. The file system and its metadata are kept in RAM. To get a file type or other more specific file information from the header the file needs to be opened. To prevent delays for getting metadata from file headers a block level cache can be configured.
Via the file level cache the administrator has control over the caching of files per folder volume(s). As an example: In a DDP with SSD and HD packs for example ingest can be to the cache with write through to spindles for a particular folder volume. At the same time DPX files in another folder volume can be cached from spindles to SSDs at the moment they are needed.
The file level cache is a unique feature of the file system AVFS. With this feature one gets SSD performance with HD capacity. A presentation of how this caching works is shown in this video:
Watch the video
How come DDPs can be clustered?
Different DDPs even of different type and build date can be clustered because the data of each file is contained in a single Data Location within a DDP or storage array.
Because AVFS and data are separate one DDP can have AVFS active while both DDPs act as a Data Location provider.